FAQ
Topics
Introduction
DLPerf
Rental Types
Instances
Networking
Jupyter
SSH
Security
Billing
Data Movement
Examples
DiscoDiffusion
StableDiffusion
Nvidia-GLX-Desktop
Bittensor
Troubleshooting
Hosting
Hosting Hardware
Introduction
What is Vast.ai?
Vast.ai is a cloud computing, matchmaking and aggregation service focused on lowering the price of compute-intensive workloads. Our software allows anyone to easily become a host by renting out their hardware. Our web search interface allows users to quickly find the best deals for compute according to their specific requirements.
How does it work in a nutshell?
Hosts download and run our management software, list their machines, configure prices and set any default jobs. Clients then find suitable machines using our flexible search interface, rent their desired machines, and finally run commands or start SSH sessions with a few clicks.
What are Vast's advantages?
Vast.ai provides a simple interface to rent powerful machines at the best possible prices, reducing GPU cloud computing costs by ~3x to 5x.
Consumer computers and consumer GPUs in particular are considerably more cost effective than equivalent enteprise hardware. We are helping the millions of underutilized consumer GPUs around the world enter the cloud computing market for the first time.
What operating systems are provided? Windows?
Vast currently provides linux docker instances, mostly Ubuntu based, no Windows.
What interface is provided?
Currently vast has ssh access (for ssh instances), jupyter instances with jupyter GUI, or a command-only instance mode. We do not provide remote desktop.
DLPerf
What is DLPerf?
DLPerf (Deep Learning Performance) - is our own scoring function. It is an approximate estimate of performance for typical deep learning tasks. Currently DLPerf predicts performance well in terms of iters/second for a few common tasks such as training resnet50 CNNs. For example on these tasks, a V100 instance with a DLPerf score of 21 is roughly ~2x faster than a 1080Ti with a DLPerf of 10.
It turns out that many tasks have similar performance characteristics, but naturally if your task is very unusual in its compute requirements the DLPerf score may not be very predictive. A single score can never be accurate for predicting performance across a wide variety of tasks; the best we can do is approximate performance on many tasks with a weighted combination. Although far from perfect, DLPerf is more useful for predicting performance than TFLops for most tasks.
In the near future we intend to improve DLPerf by incorporating search criteria into the score dynamically, and later - by using deep learning (of course!). For example, if you select the Pytorch image, the DLPerf scores will automatically adjust to predict Pytorch benchmark performance, a fp16/fp32 checkbox can provide information for even more informative scores, and so on.
Rental Types
We currently offer two rental types: On Demand (High Priority) and Interruptible (Low Priority). On Demand instances have a fixed price set by the host and run for as long as the client wants. Interruptible instances use a bidding system: clients set a bid price for their instance; the current highest bid is the instance that runs, the others are paused.
Are vast.ai interruptible instances the same as AWS spot or GCE interruptible?
They are similar but have a few key differences. AWS spot instances and GCE interruptible instances both can be interrupted by on demand instances, but they do not use a direct bidding system. In addition GCE interruptible instances can only run for 24 hours. Vast.ai interruptible instances use a direct bidding system but are otherwise not limited.
What happens when my interruptible instance loses the bid?
If another user places a higher bid or creates an on demand rental for the same resources then your instance will be stopped. Stopping an instance kills the running processes, so when you are using interruptible instances it's important to save your work to disk. Also we highly recommend having your script periodically save your outputs to cloud storage as well, because once your instance is interrupted it could be a long wait until it resumes.
Instances
How can I restart my programs once the instance restarts?
If you use the "custom command" option then your command will run automatically when the instance starts up. However if you are using an ssh instance, there is no default startup command. You can put startup commands in "/root/onstart.sh". This startup script will be found and run automatically on container startup.
I see my instance has a Lifetime - what does that mean?
Every instance offer on the Create page has a Max Duration. When you accept an offer and create an instance, this Max Duration becomes the instance lifetime and begins ticking down. When the lifetime expires, the instance is automatically stopped. The host can extend the contract which will add more lifetime to your instance, or they may not - it's up to them. Assume your instance will be lost once the lifetime expires; copy out any important data before then.
How can I set environment variables?
Use the -e docker syntax in the docker create/run options. For example to set the env variables TZC to UTC and TASKID to "TEST":
-e TZ=UTC -e TASKID="TEST"
Any environment variables you set will be visible only to your onstart script (or your entrypoint for entrypoint launch mode). When using the ssh or jupyter launch modes, your env variables will not be visible inside your ssh/tmux/jupyter session by default. To make custom environment variables visible to the shell you need to export them to /etc/environment.
Add something like the following to the end of your onstart to export any env variables containing an underscore '_':
env | grep _ >> /etc/environment;
Or to export all env variables:
env >> /etc/environment;
How can I get the instance ID from within the container?
The environment variable VAST_CONTAINERLABEL is defined in the container. Ex:
root@C.38250:~$ echo $VAST_CONTAINERLABEL
C.38250
How can I stop the instance from within the instance?
First run the following from inside the instance to create a special per instance api key and save it in the appropriate location:
cat ~/.ssh/authorized_keys | md5sum | awk '{print $1}' > ssh_key_hv; echo -n $VAST_CONTAINERLABEL | md5sum | awk '{print $1}' > instance_id_hv; head -c -1 -q ssh_key_hv instance_id_hv > ~/.vast_api_key;
Then download the CLI:
apt-get install -y wget; wget https://raw.githubusercontent.com/vast-ai/vast-python/master/vast.py -O vast; chmod +x vast;
Then test it by starting the instance (which is a no-op as the instance is already running):
./vast start instance ${VAST_CONTAINERLABEL:2}
If that works then you can stop the instance as well:
./vast stop instance ${VAST_CONTAINERLABEL:2}
Networking
How can I open custom ports?
Add -p arguments in the docker create/run options box in the image config editor pop up menu. To open ports 8081 and 8082, use something like this:
-p 8081:8081 -p 8082:8082
This will result in additional arguments to docker create/run to expose those internal ports, which will be mapped to random external ports. Any ports exposed in these docker options are in addition to ports exposed through EXPOSE commands in the docker image, and the ports 22 or 8080 which may be opened automatically for ssh or jupyter.
After the instance has loaded, you can find the corresponding external public IP:port by opening the IP Port Info pop up (button on top of the instance), and then looking for something like:
65.130.162.74:33526 -> 8081/tcp
In this case the public IP:port 65.130.162.74:33526 can be used to access anything you run on port 8081 inside the instance. As a simple test case, you can run a simple minimal web browser inside the instance with the following command:
python -m http.server 8081
Which you would then access in this example by loading 65.130.162.74:33526 in your web browser.
Jupyter
I'm getting very slow transfer speeds using the jupyter download/upload?
You probably created a proxy instance, which is the default. The proxy instance is still useful for some use cases as you can get full speed downloading files with wget, git, external ftp, cloud storage, etc. However the built-in upload/download buttons can be very slow (especially when the proxy servers are overloaded).
So if you want full speed transfers using the jupyter upload/download GUI, you need to create a direct https instance.
On the create page, select EDIT IMAGE & CONFIG, open your image template (usually pytorch), then select the direct https mode under jupyter. Then create a new instance. You will need to import a certificate (see below).
What is this HTTPS website unsecure warning?
The jupyter direct HTTPS option is faster than the proxy option, but it requires installing a new certificate in your browser:
Download the certificate file, then go into your browser certificate settings and add the new certificate. In Google Chrome you click the little 3-dot menu in the top right corner, then settings in the drop-down menu, then Privacy and security on the left, then Security in the middle, then scroll down to the Advanced section and click on Manage certificates, then the Authorities tab, and finally the Import button and select the certificate file you just downloaded (jvastai_root.cer).
I'm deleting files in Juypter but it's not freeing disk space! How do I truly delete?
By design/default the delete button in Jupyter does not actually delete files, it just moves them to the Trash folder, which is located at:
~/.local/share/Trash
So you can delete the trash folder in a terminal using rm -r:
rm -r ~/.local/share/Trash
How do I run colab notebooks?
Just select the pytorch image and create a jupyter or jupyter lab instance. Then download the colab notebook as a .ipynb file and upload it to the instance in Jupyter. Then just click on that to run the notebook. Depending on the notebook you may need to install additional dependencies with apt-get or pip. As of now we don't have a recommended colab-emulating docker image.
I'm getting some missing library or package error?
Depending on the notebook, you may have to install additional dependencies. You can do this by opening a terminal in jupyter and then using regular apt-get install PACKAGE or pip install PACKAGE.
How can I more easily download many files?
Jupyter Labs supports downloading multiple files by shift click to select multiple and then right click download option. But Jupyter Notebook only supports downloading individual files, and neither supports downloading folders/directories. You can use zip to more quickly download directories and large numbers of files. First open a terminal, and then in the terminal you can install zip and use that to zip up many files into a single package:
apt-get install -y zip
And then to zip all of the files in the "images_out/TimeToDisco" (only) directory:
zip all_images.zip images_out/TimeToDisco/*
Or zip all of the files in "images_out" including sub-directories:
zip -r all_images.zip images_out/
Jupyter is ok, but can I run colab directly with a vast instance?
Yes, but it requires a bit of setup, is more error prone, and generally not recommended. Our default jupyter (notebook or lab) launch modes generally work much better and have numerous advantages: (faster, can easily reconnect, easily manage different instances running their own notebooks, can easily share notebook links, etc).
Colab supports a 'local runtime' option to allow people to run colab connecting to their local machine, using their own GPUs. However this is a minor feature of colab and is intentionally restricted to allow only a localhost connection (perhaps to prevent using colab on competing clouds). So getting around that restriction requires using ssh forwarding to make a remote jupyter instance appear local.
Furthermore, colab is designed to connect to an ephemeral runtime instance which lasts only as long as a browser session. As a result it often has problems reconnecting to an existing runtime. This means that even if you get all this to work, you'll often have to ssh into the instance and restart jupyter after closing reopening a notebook tab in your browser.
If you still want to try this, first create a pytorch ssh instance (not jupyter). You then may need to setup your ssh keys if you haven't created an ssh instance before. You will then need to ssh connect with port forwarding. Our default ssh command for linux/mac already forwards port 8080, but if you have multiple ssh instances you will need to use different ports to avoid conflicts.
Then inside the instance you'll want to install/upgrade some packages:
apt install -y git curl ffmpeg libsm6 libxext6;
Colab can't connect at all to latest versions of Jupyter as of 7/5/2022, but these pinned versions seem to work. The first command here installs pinned versions known to work. If you are reading this much later, the 2nd command may or may not work:
install jupyter pinned:
pip install notebook==6.4.11 tornado==6.1 jupyter ipywidgets jupyter_http_over_ws widgetsnbextension pandas-profiling opencv-python pandas matplotlib regex;
or unpinned:
pip install jupyter tornado ipywidgets jupyter_http_over_ws widgetsnbextension pandas-profiling opencv-python pandas matplotlib regex;
then install extensions:
jupyter nbextension enable --py widgetsnbextension; jupyter serverextension enable --py jupyter_http_over_ws;
Then run jupyter with options like these (adjust the port 8080 to match whatever port you forwarded over ssh):
jupyter notebook --NotebookApp.allow_origin='*' --port=8080 --NotebookApp.port_retries=0 --allow-root --NotebookApp.allow_remote_access=True
That will output a couple of http addresses. You want to use the localhost address. Test it first by opening in a browser on your local machine. Then if that works, you should be able to copy paste that into colab in the "connect to local runtime". Good luck!
SSH
How do I connect to an SSH instance on linux/mac?
On Ubuntu or Mac, first you need to generate an rsa ssh public/private keypair using the command:
ssh-keygen -t rsa
Next you may need to force the daemon to load the new private key, and confirm it's loaded:
ssh-add; ssh-add -l
Then get the contents of the public key with:
cat ~/.ssh/id_rsa.pub
Copy the entire output to your clipboard, then paste that into the "Change SSH Key" text box under console/account. The key text includes the opening "ssh-rsa" part and the ending "user@something" part. If you don't copy the entire thing, it won't work.
example SSH key text:
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAZBAQDdxWwxwN5Lz7ubkMrxM57CHhVzOnZuLt5FHi7J8zFXCJHfr96w+ccBOBo2rtBBTTRDLnJjIsKLgBcC3+jGyZhpUNMFRVIJ7MeqdEHgHFvUUV/uBkb7RjbyyFcb4BCSYNggUZkMNNoNgEa3aqtBSzt47bnuGqKszs9bfACaPFtr9Wo0b8p4IYil/gfOY5kuSVwkqrBCWrg53/+T2rAk/02mWNHXyBktJAu1q9qTWcyO68JTDd0sa+4apSu+CsJMBJs3FcDDRAl3bcpiKwRbCkQ+N63ol4xDV3zQRebUc98CJPh04Gnc41W02lmdqFL2XG5U/rV8/JM7CawKiIz3dbkv bob@velocity
You can use a few SSH keys by pasting in each on a new line.
How do I connect to an SSH instance from windows?
You can use windows subsystem for linux and then follow the ssh instructions for linux/mac. But some windows users prefer a GUI tool, so here is a quick guide to connecting to an ssh instance from windows using putty. Make sure you save the key in ssh rsa-2 format.
What is this tmux thing? How do I create multiple bash terminals on my ssh instance?
We connect you to a tmux session by default for reliability. You can create a new bash terminal window with "ctrl+b,c" (press ctrl and b, followed by c), and switch with "ctrl+b,n". But google "tmux cheat sheet" or "tmux guide" for more info.
Security
How do you protect my data from other clients?
Clients are isolated to unprivileged docker containers and only have access to their own data.
How do you protect my data from providers?
There are many providers on Vast.ai, ranging from tier 4 datacenters with extensive physical and operational security down to individual hobbyists renting out a few machines in their home. Our vetted datacenter partners can provide data security similar to other large cloud providers. If data security is important for your use case, you may want to rent only from our datacenter partners.
Even though our smaller community providers generally do not have datacenter level physical or operational security, they have little to gain and much to lose from stealing customer data. It can take months for providers to accumulate trust and verified status on Vast. These verified providers are thus incentivized to maintain their reputational standing just like larger cloud providers. Hosts generally have many different clients and there are significant costs to identifying, saving, copying, and exploiting any interesting datasets, let alone any particular client's data. You can also roughly see the relative age of a provider by their ID.
Billing
How does billing work?
Once you enter a credit card and an email address and both are verified, you will receive a small amount of free test credit. Then you can increase your credit balance using one time payments with the add credit button. Whenver your credit balance hits zero or below, your instances will be stopped automatically, but not destroyed.
You are still charged storage costs for stopped instances, so it is important to destroy instances when you are done using them.
Your credit card will be automatically charged periodically to pay off any outstanding negative balance.
Can you bill my card automatically so I don't have to add credit in advance?
There is also an optional debit-mode feature which can be enabled by request for older accounts. When debit-mode is enabled, your account balance is allowed to go negative (without immediately stopping your instances).
I didn't enable debit-mode - what are these automatic charges to my card?
Your card is charged automatically regardless of whether or not you have debit-mode enabled. Instances are never free - even stopped instances have storage charges. Make sure you delete instances when you are done with them - otherwise your card will continue to be periodically charged indefinetly.
How does pricing work?
There are seperate prices and charges for 1.) base active rental costs, 2.) storage costs, and 3.) bandwidth costs. You are charged the base active rental cost for every second your instance is in the active/connected state. You are charged the storage cost (which depends on the size of your storage allocation) for every single second your instance exists, regardless of what state it is in: whether it is active or inactive, online or offline, functional or broken. Stopping an instance does not avoid storage costs. You are charged bandwidth prices for every byte sent or received to or from the instance, regardless of what state it is in. The prices for base rental, storage, and bandwidth vary considerably from machine to machine, so make sure to check them.
What is the billing frequency?
Balances are updated about once every few seconds.
Why should I trust vast.ai with my credit card info?
You don't need to: Vast.ai does not see, store or process your credit card numbers, they are passed directly to Stripe (which you can verify in the javascript).
Do you support paypal? What about crypto-currency?
We currently support only major credit cards through Stripe.
Data Movement
How do I upload/download to/from my instance?
You can use the CLI copy command to copy from/to directories on a remote instance and your local machine, or to copy data between two remote instances. You can use the copy buttons in the GUI to copy data between two remote instances. The copy command uses rsync and is generally fast and efficient, subject to single link upload/download constraints. Example:
./vast copy ~/workspace 4330147:/workspace
Currently one endpoint of the copy must involve a vast instance with open ports. For a remote->local copy or local->remote copy, the remote instance must be on a machine with open ports (although the instance itself does not need open ports), and the remote instance can be stopped/inactive. For instances on machines WITHOUT open ports, copy to/from local is not available, but you can still copy to a 2nd vast instance with open ports.
For a remote->remote copy (copy between 2 instances), the src can be stopped and does not need open ports, but the dst must be a running instance with open ports. It is not sufficient that the instance is on a machine with open ports, the instance itself must have been created with open port mappings. If the instance is created with the direct connect option (for jupyter or ssh launch modes), the instance will have at least one open port. Otherwise, for proxy or entrypoint instance types, you can get open ports using the -p option to reserve a port in the instance configuration under run options (and you must also then pick a machine with open ports).
If your data is already stored in the cloud (S3, gdrive, etc) then you should naturally use the appropriate linux CLI or commands to download and upload data directly. This generally will be one the fastest methods for moving large quantities of data, as it can fully saturate a large number of download links. If you are using multiple instances with significant data movement requirements you will want to use high bandwidth cloud storage and avoid any single machine bottlenecks.
If you launched a Jupyter notebook instance, you can use it's upload feature, but this has a file size limit and can be slow.
You can also use standard linux tools like scp, ftp, rclone, or rsync to move data. For moving code and smaller files scp is fast enough and convenient. However be warned that the default ssh connection uses a proxy and can be slow for large transfers.
How do I upload/download to/from my instance - using scp?
If you launched an ssh instance, you can copy files using scp. The default ssh connection uses a proxy and thus can be slow (in terms of latency and bandwidth). Thus we recommend only using scp over the default ssh connection for smaller transfers (less than 1 GB). For larger inbound transfers a direct connection is recommended. Downloading from a cloud data store using wget or curl can have much higher performance.
The relevant scp command syntax is:
scp -P PORT LOCAL_FILE root@IPADDR:/REMOTEDIR
The PORT and IPADDR fields must mach those from the ssh command. The "Connect" button on the instance will give you these fields in the form:
ssh -p PORT root@IPADDR -L 8080:localhost:8080
For example, if Connect gives you this:
ssh -p 7417 root@52.204.230.7 -L 8080:localhost:8080
You could use scp to upload a local file called "myfile.tar.gz" to a remote folder called "mydir" like so:
scp -P 7417 myfile.tar.gz root@52.204.230.7:/mydir
How do I upload/download to/from my instance - using scp with a direct connection?
You can setup a 2nd direct ssh connection on instances with open ports by running sshd on an open port:
/usr/sbin/sshd -p OPEN_PORT
Instances with open ports will show their IP address and port range on the top of the instance card. Once you have sshd running on an open port, you can then use ssh/scp/rsync normally with the listed IP address and open port you chose. This direct connection can be faster than the default proxy ssh connection.
I'm getting a ConnectionResetError downloading files?
This seems to be due to bugs in the urllib3 and or requests libraries used by many python packages. We recommend using wget to download large files - it is quite robust and recovers from errors gracefully.
How can I download a dataset from Google Drive using wget?
First you need to get the document ID. In My Drive file browser, right click on your file and then "Get Shareable Link". This will copy a link with the document ID to your clipboard. Paste the link to a text file, you should get something like this:
https://drive.google.com/open?id=0CwHCjDrwcJcGSHVYTkJqOVlfZ25RMk5CZENXNHFwOFdSSUJZ
The document ID in this case is 0CwHCjDrwcJcGSHVYTkJqOVlfZ25RMk5CZENXNHFwOFdSSUJZ. Now you can use the following wget command:
wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=FILEID' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=FILEID" -O FILENAME && rm -rf /tmp/cookies.txt
Replace the 2 occurences of FILEID with your document ID, and replace FILENAME with the desired output filename.
How can I download a Kaggle dataset using wget?
First you need to get the raw https link. Using the chrome browser, on the Kaggle website go to the relevant dataset or competition page and start downloading the file you want. Then cancel the download and press ctrl+j to bring up the chrome Downloads page. At the top is the most recent download with a name and a link under it. Right click on the URL link and use "copy link address". Then you can use wget with that URL as follows:
wget 'URL' --no-check-certificate -O FILENAME
Notice the URL needs to be wrapped in ' ' single quotes.
Examples
Disco Diffusion
Disco diffusion is powerful free and open source AI image generator, which is easy to use on vast.ai. With the right settings and powerful GPUs, it can generate artist quality high-res images for a wide variety of subjects. All of these images were generated purely through DD on vast.ai, without any other tools or clean up. Click on any thumbnail for a full res version:














There are numerous options for running Disco Diffusion on vast, but two good options are 1.) using the pytorch docker image and a slightly modified notebook, or 2.) using a custom docker image (fork) made specifically to run DD in docker, such as jinaai/discoart. The latter custom docker image can spin up somewhat faster and has a number of advanced features beyond the original notebook, but currently requries cuda >= 11.6, which limits machine options.
1.) The disco diffusion notebooks were created for colab, but they will run in docker on vast using the common pytorch image with some slight modifications (to install a few required libs). You can use one of our slightly modified DD notebooks (5.6, 5.4, 5.2 ) to get started quickly.
Here is a quick video tutorial.
You'll want to create a jupyter instance with the pytorch image, and you'll probably want about 30 GB of disk to store the various models and to save all the beautiful high-res images you will be generating. (This is important! Make sure to choose a storage allocation before creating the instance - as you currently can not resize the instance disk allocation and running out of space can be catastrophic.)
Download the notebook (5.6, 5.4, 5.2 ) as a .ipynb file, then upload it to your jupyter instance created from the pytorch/pytorch image. Click on the notebook to run it.
Then just run fast forward the notebook or step through each cell. It can take 15 minutes or so to download the models, depending on instance internet speed. The cell (4. Diffuse) near the end shows the in-progress output image. By default it only updates every 50 steps, but you can change this via the display_rate variable in that cell - setting it to 1 shows the result of each iteration.
2.) Instead of the pytorch image, you can use the custom jinaai/discoart docker image. For this image we recommend adding the environment variable option -e JUPYTER_DIR=discoart (or JUPYTER_DIR=/ ) to your docker run options (directly under the image tag). This will instruct jupyter to start in a more sensible directory rather than /app which is basically empty. If you set this env variable you'll see the discoart.ipynb notebook file is already there in the /discoart folder, no need to upload.
If you are using Jupyter Labs you can select multiple files (using the shift key), and then download all of them one after another. Jupyter Notebook only supports downloading individual files, and neither Labs nor Notebook support downloading folders. To more conveniently download folders or a number of files, you can use the command line zip tool. First open a new terminal, and then in the terminal run the following:
apt-get install -y zip
And then to zip all of the files in the default images_out/TimeToDisco directory:
zip all_images.zip images_out/TimeToDisco/*
Note: do no use spaces in your folder names, they cause headaches on linux! Use the '_' underscore instead.
For discussion/help/advice running DD on vast find us on our discord, and make sure to check out the main DD discord .
Stable Diffusion
Stable Diffusion is a newer image diffusion generator which is generally much faster that disco diffusion, and requires less RAM. It is easy to use on Vast.ai with the Automatic111 web UI.
You can just use one of the runpod/stable-diffusion docker images which has the models included. Select a specific docker image version tag such as "runpod/stable-diffusion:web-automatic-1.5.6", ssh direct launch mode, then add "-p 3000:3000" under Docker create/run options and "/start.sh" for the onstart. Example configuration: (you may need to adjust based on which image version you want)
Docker image tag: runpod/stable-diffusion:web-automatic-1.5.6
Launch mode: SSH (with direct connect option)
Create/Run options: -p 3000:3000
Onstart: touch ~/.no_auto_tmux; /start.sh
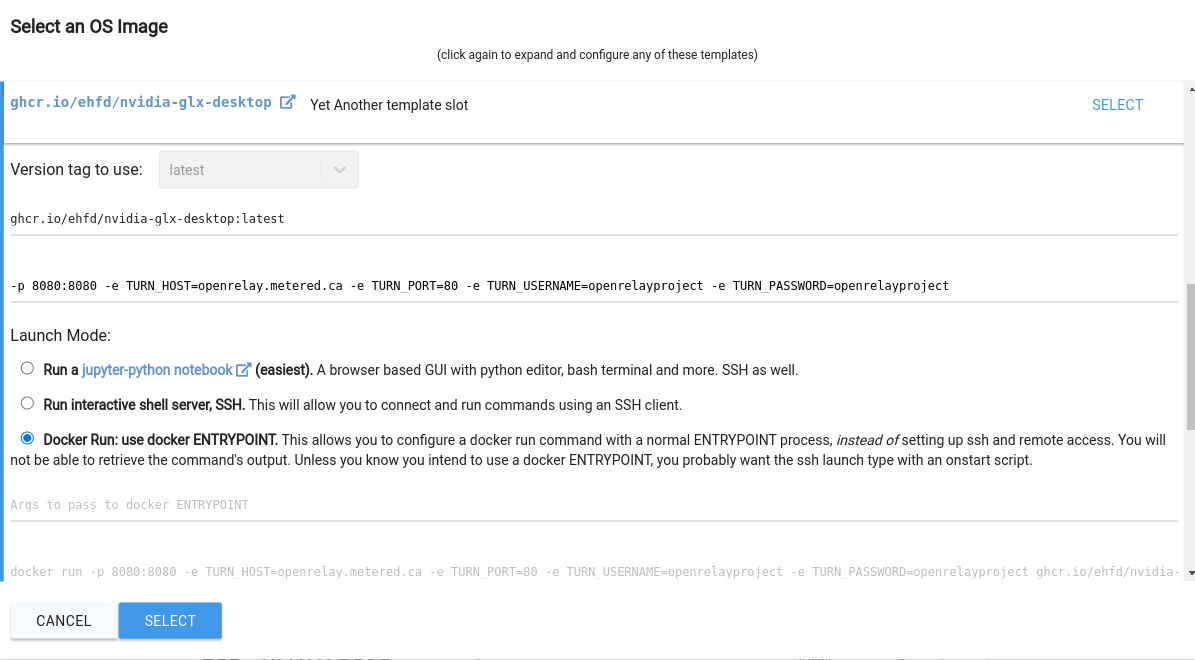
Nvidia-GLX-Desktop
Nvidia-GLX-Desktop is a docker image which provides a virtual desktop with GPU acceleration. On some (but not all) machines it requires specifying an external webRTC TURN server. To run this image on vast, just use the custom docker image:
ghcr.io/ehfd/nvidia-glx-desktop:latest
(or another tag), and then expose port 8080 and setup a TURN server in the docker run options (naturally alternative valid TURN servers should also work):
-p 8080:8080 -e TURN_HOST=openrelay.metered.ca -e TURN_PORT=80 -e TURN_USERNAME=openrelayproject -e TURN_PASSWORD=openrelayproject
Then use the docker run ENTRYPOINT launch mode and select a machine with open ports (you can use the filters on the left for port count). The image is large and may take a bit to download and start, but once it does the connect button should take you to a login screen. The default username is user and the default password is mypasswd . You can change these with -e env variables (see the linked page for details).
Example config:
Bittensor
Bittensor is a decentralized, blockchain-based machine learning network.
Vast has a wide variety of affordable GPUs which are ideal for running the Bittensor GPU miner. The setup is mostly straightforward except that Bittensor expects an open port which is identity mapped (external and internal are the same), which is possible on vast using out of range 'virtual' ports.
First open up the image config editor and pick a docker image: the opentensorfdn/bittensor repo on dockerhub has several tags. The latest as of 11/15/2022 is:
opentensorfdn/bittensor:3.4.2-torch1.12.0-cuda11.3-cubit1.1.2-pm2
And you'll probably want to select ssh launch mode.
Then you'll need to expose one or more open ports (you may want one for each miner). In this example I will setup 2 virtual ports. Ports above 66000 are considered virtual and the system will remap both the external and internal port to the same available port on the host machine. Add something like this to your docker create/run options:
-p 70000:70000 -p 70001:70001
Next we need to make sure these ports are exposed as env variables. The system already exposes the dynamic ports to env variables of the form VAST_TCP_PORT_70000, which you can use in your onstart script. However ssh by default overrides all the env variables for each new ssh session, loading a new env from /etc/environment. So you can add the following command to your onstart script to ensure the proper env variables are copied over to your ssh session:
export PATH=/root/.nvm/versions/node/v16.18.0/bin:$PATH; env >> /etc/environment; echo PATH="'$PATH'" >> /root/.bashrc;
You will also want to select the ssh connection mode, and the direct connect option. Your config should look something like this:
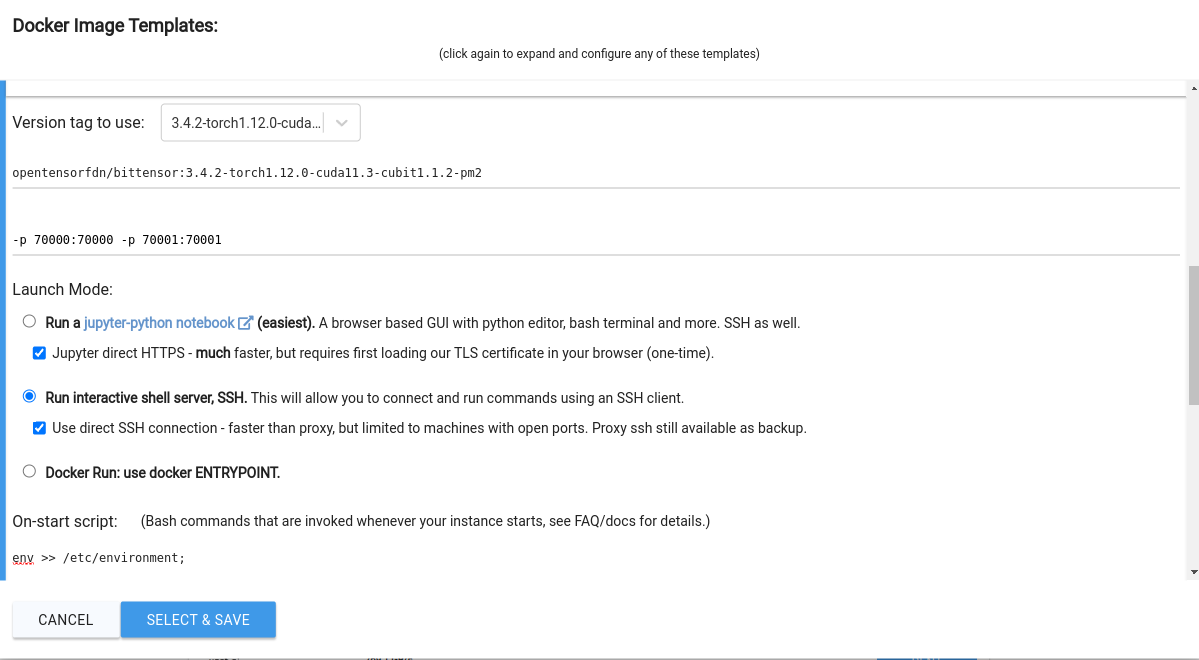
After that select a suitable machine, and connect with ssh. You can then test to make sure the dynamic ports were mapped correctly:
echo $VAST_TCP_PORT_70000
Then you will want to import or generate your wallet cold and hot keys. For testing purposes you can create a new wallet coldkey "coldkey" and hotkey "1" with these commands:
btcli new_coldkey --wallet.name coldkey
btcli new_hotkey --wallet.name coldkey --wallet.hotkey 1
IMPORTANT: For secure production use you should create your actual coldkey only on your own personal machine that you control, not on a remote cloud server. You can then import the public key on your cloud instance using btcli regen_coldkeypub:
btcli regen_coldkeypub --ss58 WALLET_ADDRESS
Replace WALLET_ADDRESS with the ss58 address of the coldkey to regen. See the bittensor docs and discord for more info.
If pm2 is not available, you may need to update the path:
export PATH=/root/.nvm/versions/node/v16.18.0/bin:$PATH;
You should now be able to use the command pm2. If this doesn't work, then you may need to find pm2 and adjust the above export command (this can happen if you are using a newer version of bittensor). You can find the latest version in the directory above using a command like:
ls -l /root/.nvm/versions/node/
Then find the latest version and update the export command as needed.
For more info see the bittensor installation documentation .
And finally you should first run bittensor on the nobunaga test network to make sure everything works before spending a long time registering on the main network. Here is an example command for testing on the nobunaga testnet using "coldkey" and "1":
btcli register --subtensor.network nobunaga --wallet.name coldkey --subtensor.register.cuda.use_cuda --subtensor.register.cuda.dev_id 0 --subtensor.register.cuda.TPB 512 --subtensor.register.cuda.update_interval 70_000 --no_prompt --wallet.hotkey 1; python3 ~/.bittensor/bittensor/bittensor/_neuron/text/core_server/main.py --logging.debug --neuron.model_name EleutherAI/gpt-neo-1.3B --neuron.autocast --neuron.device 'cuda:0' --axon.port $VAST_TCP_PORT_70000 --subtensor.network nobunaga --wallet.name coldkey --subtensor.register.cuda.use_cuda --subtensor.register.cuda.dev_id 0 --subtensor.register.cuda.TPB 512 --subtensor.register.cuda.update_interval 70_000 --no_prompt --wallet.hotkey 1;
Troubleshooting
All my instances keep stopping, switching to inactive status, even though I didn't press the stop button. What's going on?
Check your credit balance. If it hits zero or below, your instances will be stopped automatically.
I keep getting this error: spend_rate_limit. What's going on?
There is a spend rate limit for new accounts. The limit is extremely small for unverified accounts, so make sure to verify your email. The limit increases over time, so try a cheaper instance type or wait a few hours. If you are still having trouble, use the online support chat in the lower right.
I tried to connect with ssh and it asked for a password. What is the password?
There is no ssh password, we use ssh key authentication. If ssh asks for a password, typically this means there is something wrong with the ssh key that you entered or your ssh client is misconfigured. On Ubuntu or Mac, first you need to generate an rsa ssh public/private keypair using the command:
ssh-keygen -t rsa
Next you may need to force the daemon to load the new private key, and confirm it's loaded:
ssh-add; ssh-add -l
Then get the contents of the public key with:
cat ~/.ssh/id_rsa.pub
Copy the entire output to your clipboard, then paste that into the "Change SSH Key" text box under console/account. The key text includes the opening "ssh-rsa" part and the ending "user@something" part. If you don't copy the entire thing, it won't work.
example SSH key text:
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDdxWwxwN5Lz7ubkMrxM5FCHhVzOnZuLt5FHi7J8zFXCJHfr96w+ccBOBo2rtBBTTRDLnJjIsKLgBcC3+jGyZhpUNMFRVIJ7MeqdEHgHFvUUV/uBkb7RjbyyFcb4BCSYNggUZkMNNoNgEa3aqtBSzt47bnuGqqszs9bfDCaPFtr9Wo0b8p4IYil/gfOYBkuSVwkqrBCWrg53/+T2rAk/02mWNHXyBktJAu1q7qTWcyO68JTDd0sa+4apSu+CsJMBJs3FcDDRAl3bcpiKwRbCkQ+N6sol4xDV3zQRebUc98CJPh04Gnc41W02lmdqGL2XG5U/rV8/JM7CawKiIz3dbkv bob@velocity
I stopped my instance, and now when I try to restart it the status is stuck on "scheduling". What is wrong?
When you stop an instance, the gpu(s) it was using may get reassigned. When you later then try to restart the instance, it tries to get those gpu(s) back - that is the "scheduling" phase. If another high priority job is currently using any of the same gpu(s), your instance will be stuck in "scheduling" phase until the conflicting jobs are done. We know this is not ideal, and we are working on ways to migrate containers across gpus and machines, but until then we recommend not stopping an instance unless you are ok with the risk of waiting a while to restart it.
Hosting
How much money can a host make?
It's complicated; it depends on many factors (hardware performance, price, reliablity, etc).
You can estimate your hardware's earning potential by comparing to similar hardware already rented on Vast.ai. Pricing statistics over time are tracked on 500farm . Or got to the create console page select "Include Unavailable Offers" and the nvidia/opencl image to see most instance types including those fully rented.
Hosts can run low priority jobs on their own machines, so there is always a fallback when high priority jobs are not available.
How and when will I be paid for hosting?
For users in the United States, we support payout to a bank account (ACH) via Stripe. International users can receive payout through paypal or wise. Due to various transaction fees, there is a minimum payout of $20 (or equivalent in other currencies). Host billing runs on a regular weekly schedule every Friday. Host invoices are then paid out the following week, depending on bank transfer times.
Do you support payout in any crypto-currencies?
No, not at this time.
What is the revenue/fee structure?
Hosts receive 75% of the revenue earned from successful jobs, with 25% kept by Vast.ai.
What happens if I turn off my machine or just lose internet during a compute job?
Hosts are expected to provide reliable machines. We track data on disconnects, outages, and other errors; this data is then be used to estimate a host machine's future reliability. These reliability score estimates are displayed on the listing cards and also used as a factor in the default 'auto' ranking criteria.
What security measures protect my machine and my network?
Guests are contained to an isolated operating system image using Linux containers. Containers provide the right combination of performance, security, and reliability for our use case. The guest only has access to devices and resources explicitly granted to them by their contract.
Will guests be able to determine my IP address?
We do not by default prevent a guest from finding your router or NAT's external facing IP address by visiting some third party website, as this would require a full proxy network and all the associated bandwidth charges. It is essential that guests be able to download large datasets affordably. For many users a properly configured NAT/firewall should already provide protection enough against any consequences of a revealed IP address. For those who want additional peace of mind, we suggest configuring a separate network for your hosted machines. (But do make sure they can reach each other locally!)
How do I set prices?
There are two prices to consider: the max price and the min price. The max price is what on demand rentals pay, and as a host you can set that price on the Host/Machines page with the Set Prices button. As a host you can set a min bid price for your machine by creating an idle job at that price on the Host/Create Job page. If you don't want to setup a true mining idle job, you can just use "ubuntu" as the image and "bash" as the command. See the Host Setup page for more info on idle jobs.
Someone is renting my machine for less than my price, what's happening?
They are using a bid. The price that hosts set on the Host/Machines page is not the rental price. It is the maximum rental price. On demand instances pay the max price, but interruptible instances use a bidding system. You can control the min bid price by setting up an idle job. Alternatively, you can use the CLI to set a per machine min bid (reserve) price.
How do I remove a GPU from my machine?
Removing gpus is currently not supported. If you really need to remove a gpu, you will need to unlist the machine and wait for 0 rentals. Then, when it is safe, you can recreate the machine. You can do this by deleting the file: /var/lib/vastai_kaalia/machine_id
What will the stability of earnings be like?
The demand for DL compute has grown stably and significantly in the last few years; this growth is expected to continue for the forseeable future by most market analysts, and Nvidia's stock has skyrocketed accordingly. Demand for general GPU compute is less volatile than demand for cryptocurrency hashing. The stability of any particular host's earnings naturally depends on their hardware relative to the rest of the evolving market.
The slowdown in Moore's Law implies that hardware will last longer in the future. Amazon is still running Tesla K80's profitably now almost 4 years after their release, and the Kepler architecture they use is now about 6 years old.
What operating systems are supported for hosting?
Initially we are supporting Ubuntu Linux, more specifically Ubuntu 16.04 LTS. We expect that deep learning is the most important initial use case and currently the deep learning software ecosystem runs on Ubuntu. If you are a Windows or Mac user, don't worry, Ubuntu is easy and quick to install. If you are a current Windows user, it is also simple to setup Ubuntu in a dual-boot mode. Our software automatically helps you install the required dependencies on top of Ubuntu 16.04.
Hardware
What are the hardware requirements for hosting?
Technically if our software detects recent/decent Nvidia GPUs (GTX 10XX series) we will probably allow you to join, but naturally that doesn't guarantee any revenue. What truly matters is your hardware's actual performance on real customer workloads, which can be estimated from benchmarks.
Deep Learning is GPU-intensive but also requires some IO and CPU performance per GPU to feed them with data. Multi-GPU systems are preferable for faster training through parallelization but also require more total system performance in proportion, and parallel training can require more pcie bandwidth per GPU in particular. Rendering and many other workloads have similiar requirements.
What kind of hardware works best for Deep Learning?
It depends heavily on the model and libraries used; it's constantly evolving; it's complicated. We suggest looking into the various deep learning workstations offered today for some examples, and see this in-depth discussion on hackernews . GPU workstations built for deep learning are similar to those built for rendering or other compute intensive tasks.